11.2 Text Mining
Amazon product reviews, Yelp, reddit, twitter feeds, facebook, and LinkedIn are some of the sites that are text-mined to provide market research, sentiment analysis and in many cases to build a data product. An example of a data product I use are tradingviews.com and stocktwits.com. One of the features they provide are to measure publicly traded - bullish or bearish sentiments. These are valuable tools for investors and day traders. Rather than reviewing pages and pages of tweets or reddit post, a person can visualize the sentiment of users based on there comment, timeframe (i.e. day, week, month, quarter etc.) in a simple graph.
Here is a basic example of text mining:
# Mining our openning paragraph
samp_text <- "This is the final course of the specialization. It combines all the knowledge and skills learned during the course - from understanding data science, to installing R and RStudio, loading, subsetting, wrangling, exploring, using statistical inference, training, and testing our data sets based on applicable machine learning. The capstone is a partnership between Johns Hopkins University and Swiftkey. I have used this product a while back in 2013-2015. I was amazed at the innovation on digital keyboards. The ability to slide your finger across the keyboard without lifting it. It then predicts the word with high accuracy. This course provides a blueprint on how to achieve the word prediction technology behind it."
# 10 most frequent terms
sampdf <- data_frame(text = samp_text) %>%
unnest_tokens(word, text) %>% # split words
anti_join(stop_words) %>% # take out "a", "an", "the", etc.
count(word, sort = TRUE) # count occurrences
sampdf[1:10,] %>% kable(caption = 'Text Mining') %>% kableExtra::kable_styling()| word | n |
|---|---|
| data | 2 |
| word | 2 |
| 2013 | 1 |
| 2015 | 1 |
| ability | 1 |
| accuracy | 1 |
| achieve | 1 |
| amazed | 1 |
| applicable | 1 |
| based | 1 |
sampdf[1:5,] %>% ggplot(aes(y=reorder(word,n), x=n))+geom_col()+labs(y= "Words/Characters", x="Frequency", title = "Text Mining")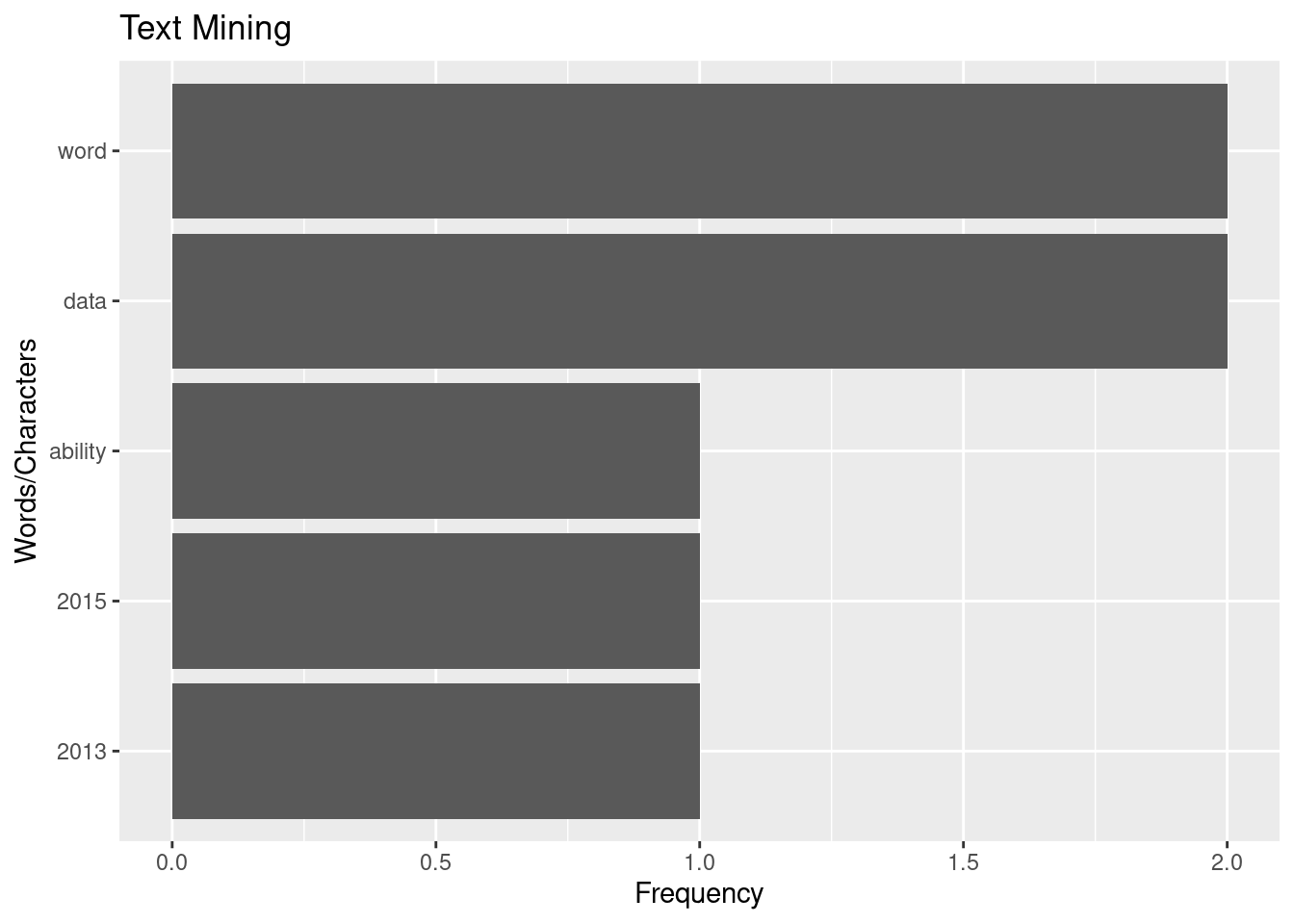
We can visually see “word” and “data” are the most frequent words in our paragraph. It makes sense since the topic is analyzing text data. Let’s go on to the next topic of Corpus.